




Conversations is the ability to have a continuous conversation about some subject with the chatbot, such that the chatbot has short term memory, remembering the subject you're talking about. Imagine the following interaction with the chatbot.
Q - What is Acme, Inc?
A - Acme is a company delivering services to blah, blah
Q - Who is its CEO?
A - Acme's CEO is John Doe
Without short term memory, allowing the chatbot to continue in a conversational manner, the chatbot would not understand what company's CEO you're interested in on the second question above. This feature is now fully working in our ChatGPT website chatbots. The quality increase this tiny little feature brings to our chatbots is difficult to overestimate. Basically, the quantitative "intelligence" of our chatbot technology increases 10x because of this tiny little bug fix.
How AI short term memory works
The way our chatbot's short term memory works is that when you ask the chatbot a question, it will find relevant training snippets from your training data using semantic AI search. This becomes a "context" from which ChatGPT answers questions related to. Typically it only uses some 5% of your context, and the context typically contains a lot of additional facts it simply ignores. The default context size for a chatbot created using our technology is 2,000 tokens, and a typical answer from ChatGPT is less than 100 tokens. This implies that 95% of the context is not used in its first answer.
However, this allows you to ask follow up questions, and if your consecutive questions does not trigger a new context, it will reuse the same context in the follow up questions, allowing you to continue asking questions related to the context. The net effect becomes that the chatbot technology simulates the way the human brain works, allowing it to have conversations with others around some topic.
By playing with the threshold, and the maximum context tokens of your chatbot's configuration settings, you can change its "short term memory" and either increase it or decrease it. The correct settings varies with each individual chatbot, and you'll need to experiment here, but the default settings here are.
2,000 context tokens
0.75 threshold
AI hallucinations
AI hallucinations are when a Large Language Model is asked a question it doesn't know the answer to. With our technology, such hallucinations are almost possible to get completely rid of. This is done by reducing the "threshold" setting on your model, such that it always finds context to converse about. At which point if asked a question the context doesn't know an answer to, the chatbot will return something such as follows.
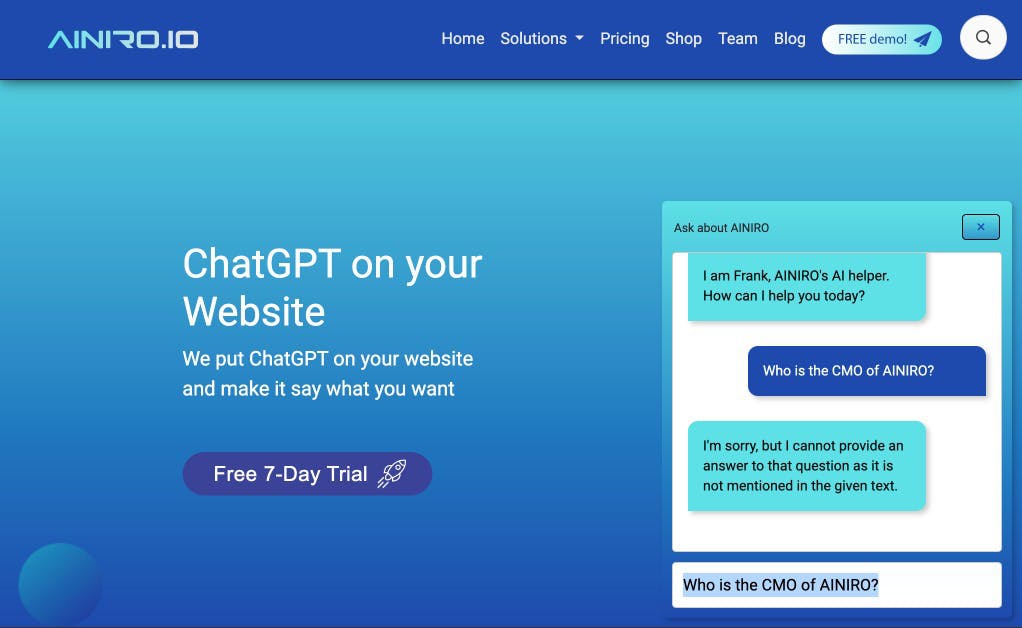
The reason is because the prompt we're actually sending to ChatGPT asks it to "find the answer to the following question using the provided context". This results in that if the context does not contain the answer to the question, ChatGPT will let you know it does not know the answer to the question, instead of starting to wildly hallucinate, making random stuff up. For a customer support chatbot that needs to be extremely accurate in its response, this becomes a crucial feature for obvious reasons.
To understand what happens in the above question where it can't tell you who our CMO is, realise it's probably using our team page as its context for the above question. Then it sends the question to ChatGPT, and asks ChatGPT to answer the question given the specified context. Since our team page doesn't mention any CMO, ChatGPT tells you it can't answer your question. Without a context here, it would start hallucinating, making stuff up.
If you have problems with AI hallucinations on a chatbot created with our technology, your goto solution should be to reduce the threshold of your model, such that it always find a context for your users questions. If you set it to 0.5 or less, typically the chatbot will never answer questions it cannot find the answer to in your training data. This is probably overdoing things though, for reasons we'll discuss in the next section.
AI leaks (it's mostly a good thing)
For most chatbots you still want the the AI model to have some "leaking". A leak is when a question does not trigger context data at all. Without "leaking", it becomes impossible to have conversations, bcause every single new question will trigger a new context, wiping out the chatbot's short term memory. Every question becomes a "new session" if you put the threshold value too low. In addition, you probably want to leverage ChatGPT's "long term memory" too, such that your chatbot is able to answer questions that ChatGPT knows the answer to, but your training data does not reference. A good example can be seen by asking our chatbot "How to cook a banana".
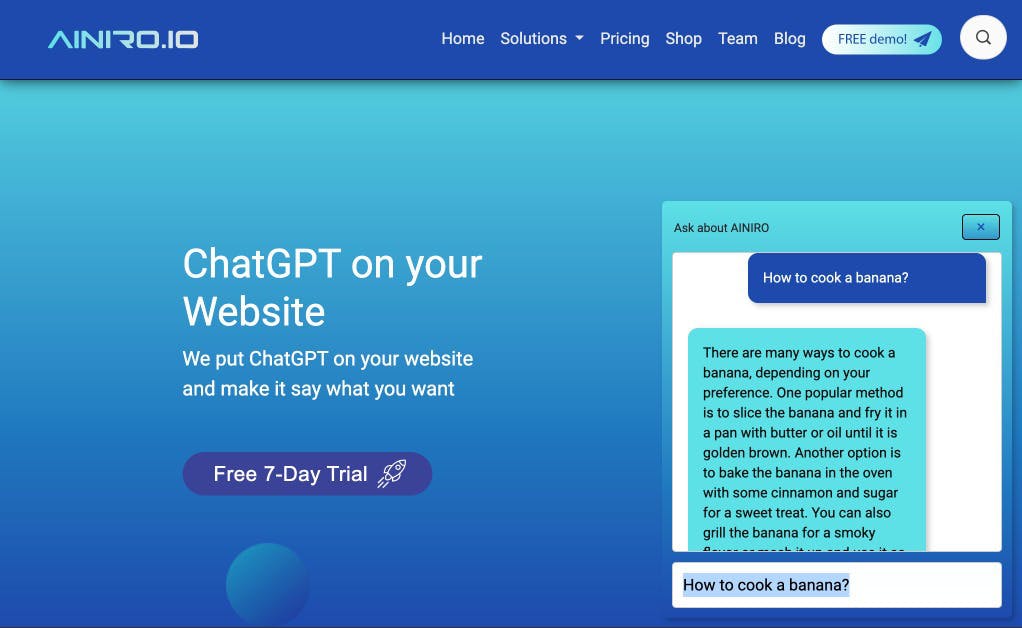
We obviously don't have any banana recipies in our training data, so what happens, is that our semantic AI search algorithms doesn't find anything it can use as a context, and therefor we invoke ChatGPT without any context at all, and the default ChatGPT takes over the process of answering the questions - Without any context specified from us.
We refer to this is "AI leaking", and it's kind of a unique thing with our technology, and for some chatbots this is a good thing. Without such "leaking" it would never leverage ChatGPT's default knowledge in any ways. Whether or not you want your chatbot to "leak" or not, needs to be individually determined on an individual basis for each chatbot you create. Yet again, reducing the threshold of your model, avoids leaks, since it'll always find training data related to a question once the threshold goes below 0.6 or 0.5 or something.
Conclusion
What we are doing, and other similar companies too for that matter, is basically just "fancy AI based prompt engineering" based upon your existing data. The two most important settings to change in these regards for you, are "Context maximum size" and "Threshold". If you play with these two settings, you can fine-tune our technology's "prompt engineering algorithms" to exactly match your requirements, on a per model basis.
However, there's a reason why we have turned off the ability to create demo chatbots in a DIY style, except for our partners. That reason is because we've got the process of setting up a chatbot down to a science - Resulting in that we can create a chatbot for you that 100% correctly answers any questions asked in a couple of hours. While we know from experience that most others will need to spend dozens and sometimes hundreds of hours to end up with the same quality result as we can get you in a couple of hours.
The irony here is that even though our company is based upon automation, it still needs a "human touch" to configure your automation, such that you end up getting high quality results. This is why we charge €498 in setup, because we'll spend hours setting up a kick ass chatbot for you, that becomes 100% correct, instead of 50% or 80% - That probably is the maximum you're able to bring an AI-based website chatbot up to using your own training data without understanding how the technology works.
This is why we insist upon holding a several hour long course for partners, every time we bring a new partner on board - Because the partner's ability to deliver super high quality chatbots to his or her clients, reflects back on us as a company. In addition to a course, Aria have created training material for partners that is more than 100 pages long, explaining every single checkbox and button, and how it reflects upon the chatbot's quality. If you want to talk to us about super high quality chatbots, or become a partner of us, you can contact us below.